Visual Comparison of Depth-Anything-V2 Depth Map Generation Models (Large, Base, Small)
 Let’s see what we have here
Let’s see what we have here
This article reviews the Depth-Anything-V2 models and serves as a companion to the article on how to create stereoscopic 3D video from any source 2D. Here we’ll compare the quality of depth maps obtained from all available models - Large, Base, and Small. There will be many images and minimal text.
For clarity, the depth maps are colorized (COLORMAP_JET). The scale ranges from dark red (near objects) to dark blue (far objects).
Brief overview of the models:
- Large: 335.3M parameters, size ~1280MB.
- Base: 97.5M parameters, size ~372MB.
- Small: 24.8M parameters, size ~95MB.
The Depth-Anything-V2 page also mentions a Giant model with 1.3B parameters, but it’s not yet available for download.
As a reminder from the main article, here’s a speed comparison for processing a test set of 100 frames for each model (running in 2 threads):
- The Large: 1 minute 9 seconds, maximum VRAM usage (excluding reserved memory, here and throughout): 3994.97 MB.
- The Base: 24.47 seconds, maximum VRAM usage: 2415.44 MB.
- The Small: 11.59 seconds, maximum VRAM usage: 1134.84 MB.
Let’s take the following as axioms:
- The Large model generally works more accurately, sees more objects and details, and defines object contours more sharply.
- The Base model is on average worse than Large, but often not significantly. It usually sees fewer objects and details.
- The Small model sees the fewest details and doesn’t define object contours clearly.
Now let’s look at examples.
 Source image
Source image
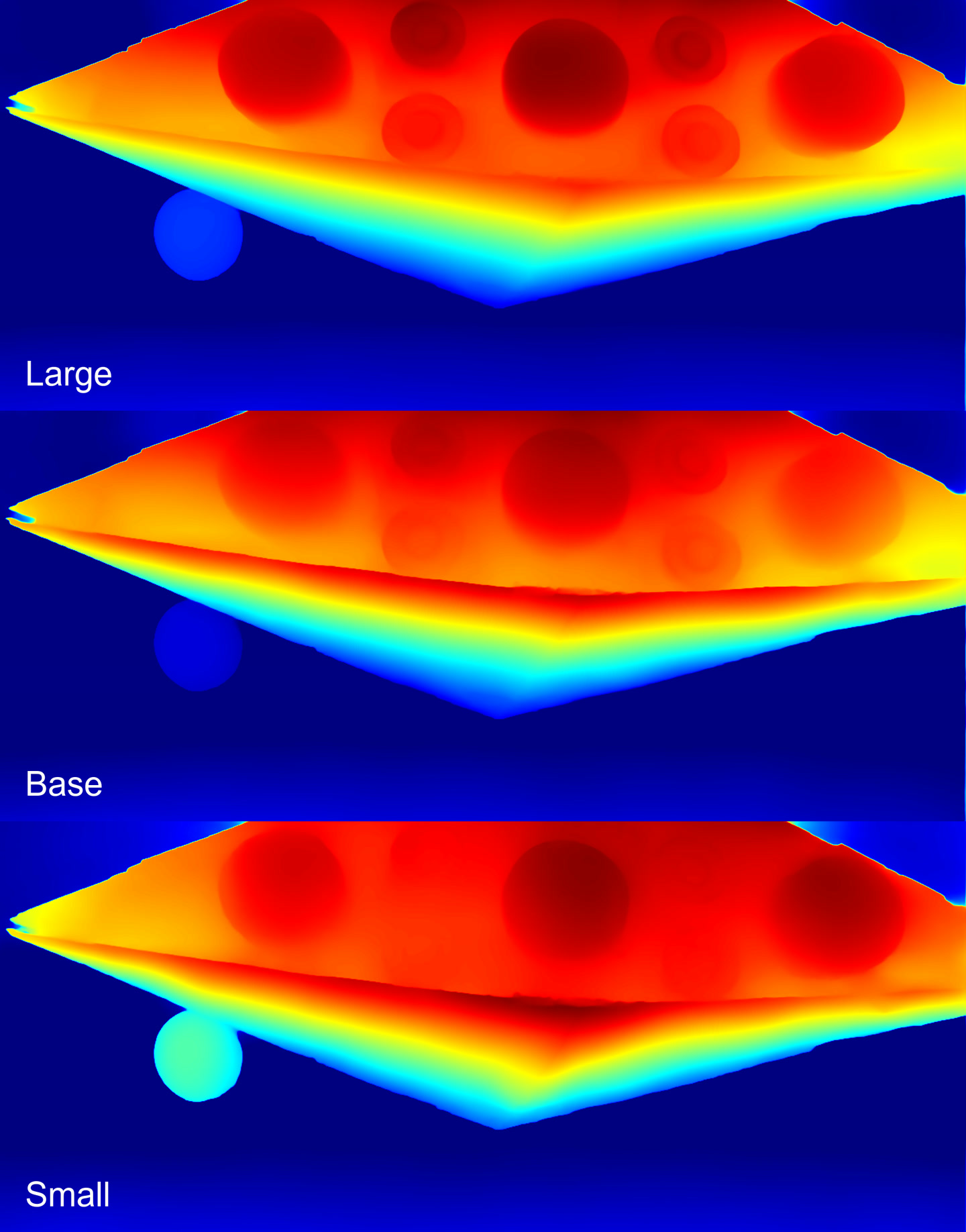 Depth maps
Depth maps
Overall, both the Large and the Base identified the objects and their depth well. The engines are visible in greater detail on the Large model. However, the Small model poorly distinguished the engines and incorrectly associated the satellite with the ship, even though the satellite was clearly located farther away.
Next image:
 Source image
Source image
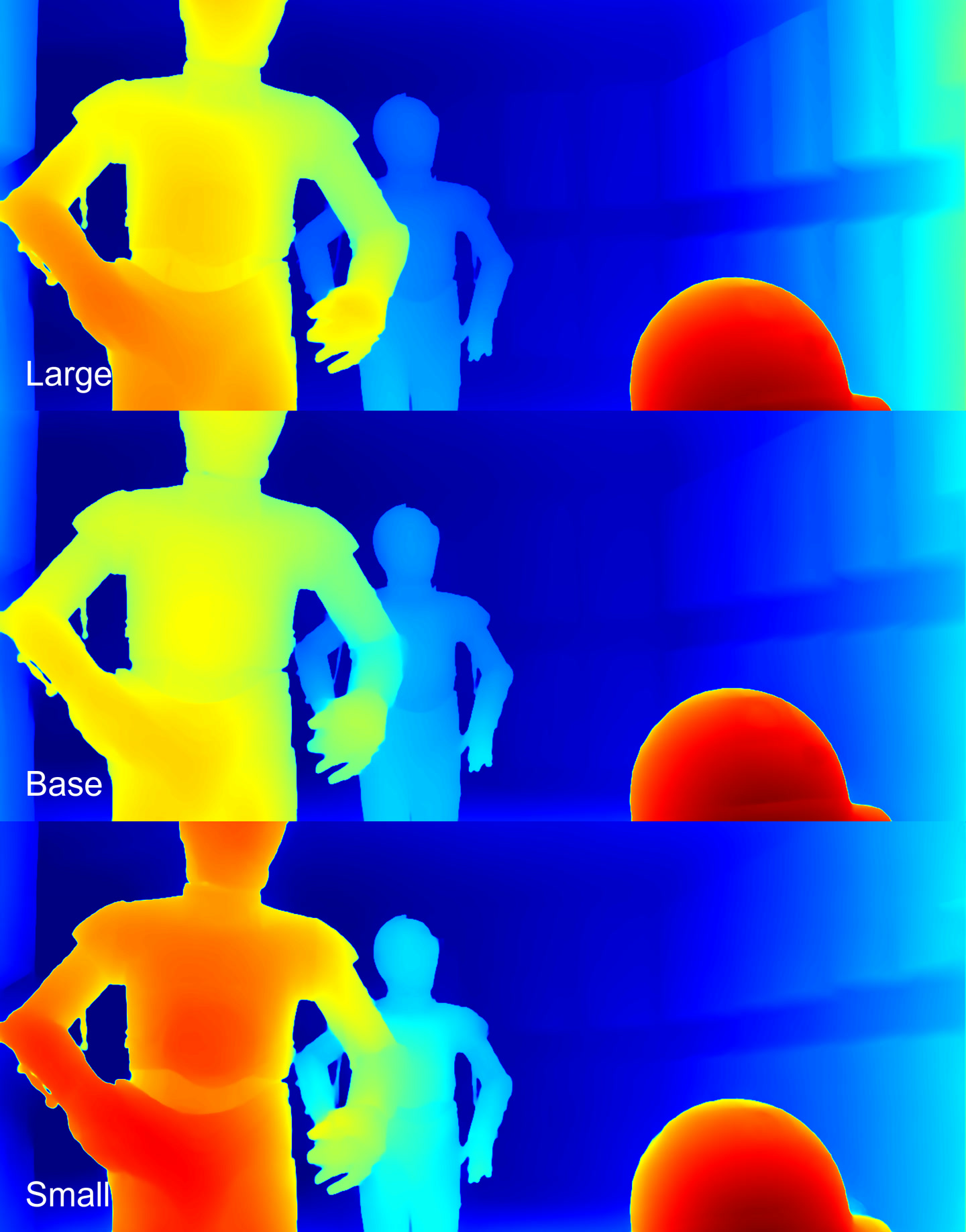 Depth maps
Depth maps
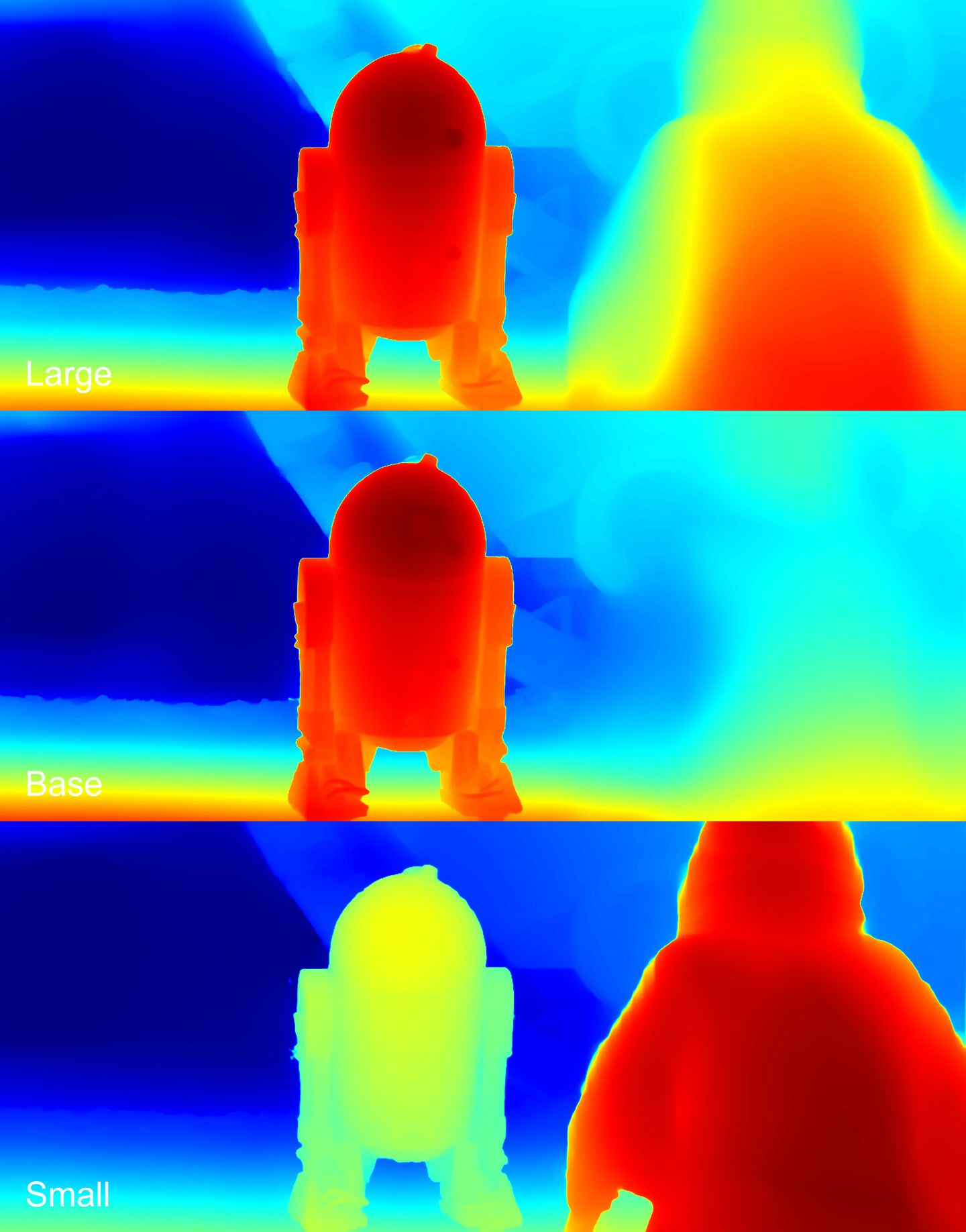
Overall, all models performed well. On the Large and the Base, R2-D2 (the droid on the right) is closer to the camera, while on the Small he’s level with his friend on the left. It’s difficult to judge from this frame which is correct. The Large model better perceived the wall structure, with nearly all blocks clearly defined.
Next image:
 Source image
Source image
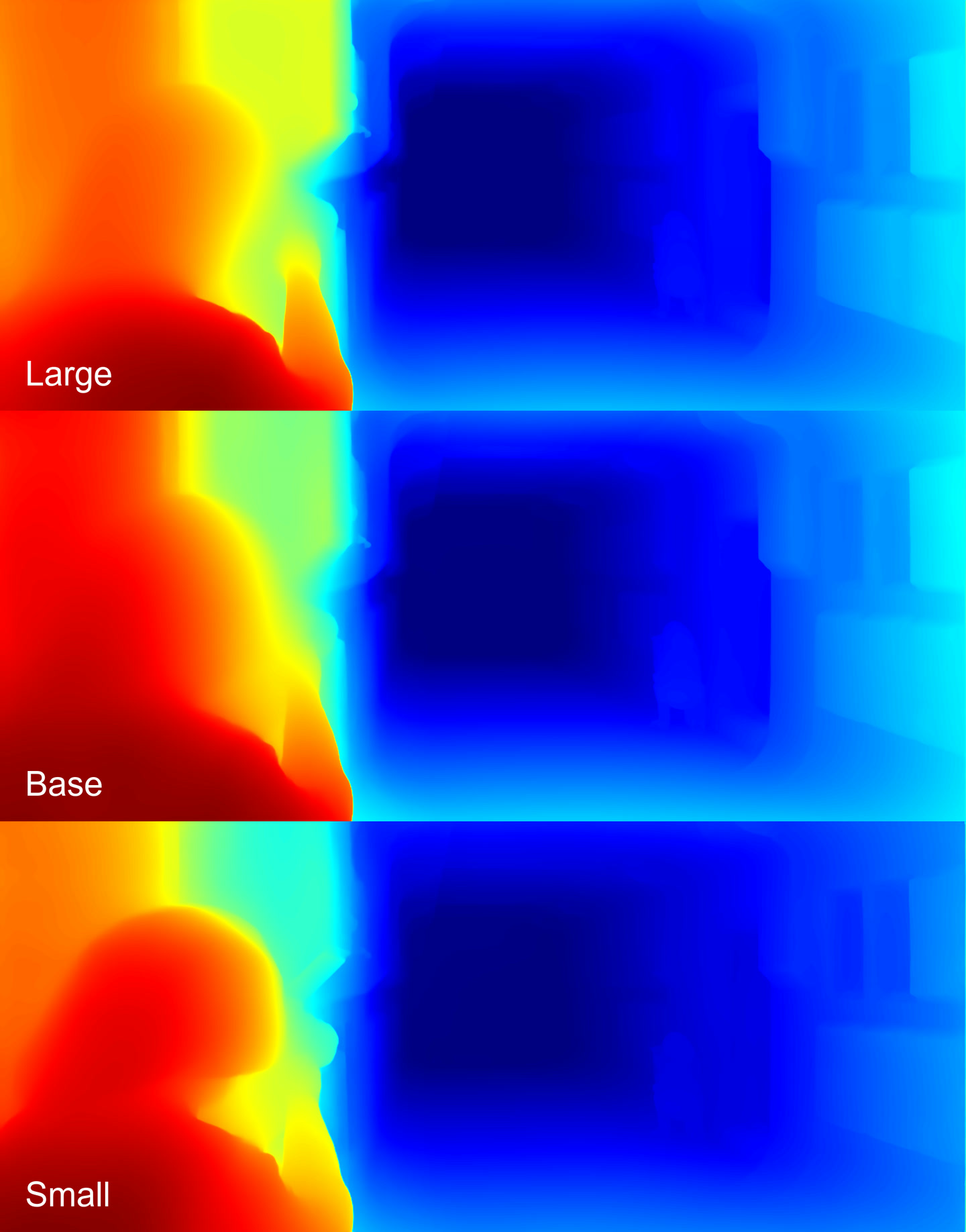 Depth maps
Depth maps
The Large and the Base models performed almost identically, and both poorly defined the character on the left. However, the Small model accurately identified this character and defined the character on the right more sharply. The Small model won here.
Next image:
 Source image
Source image
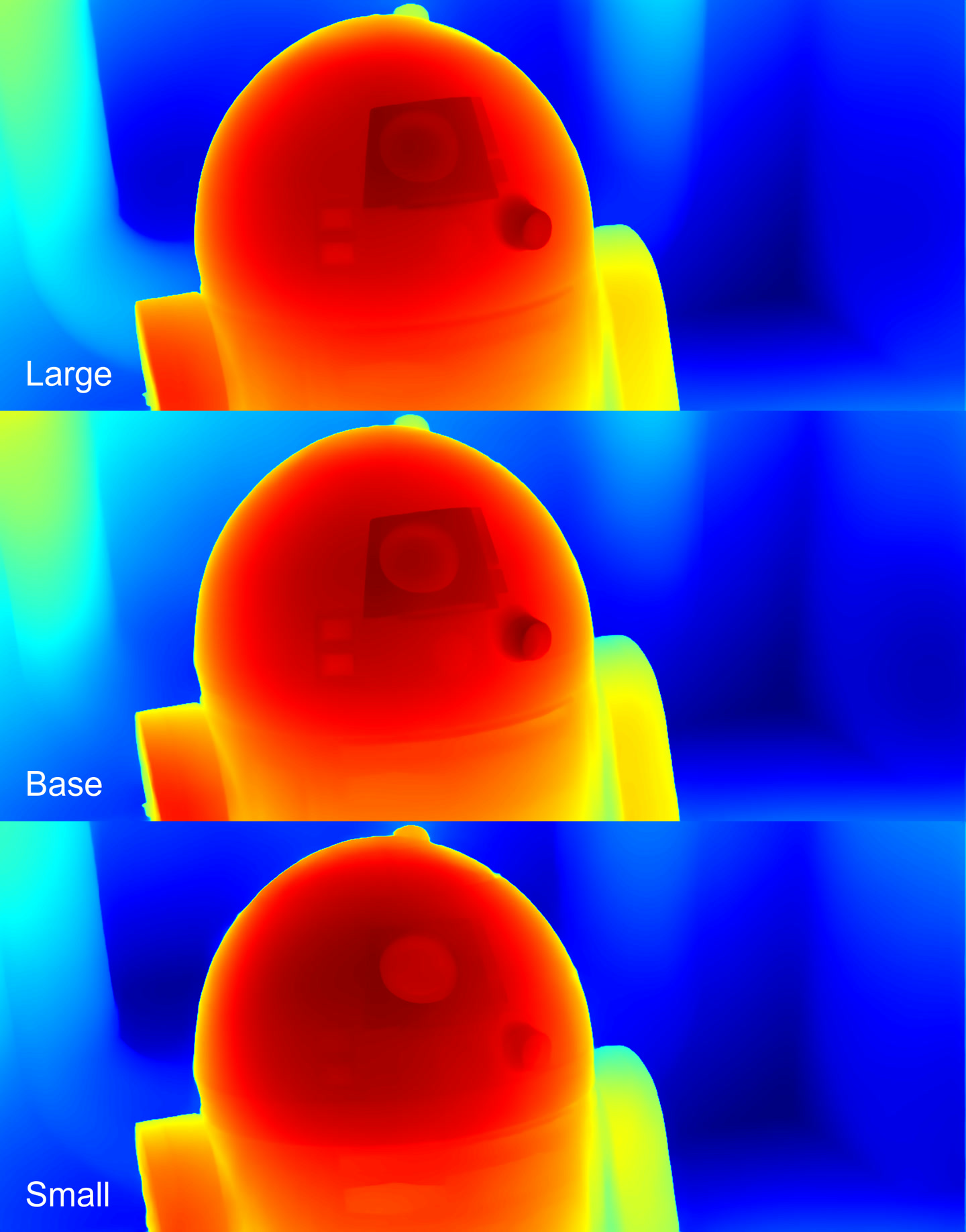 Depth maps
Depth maps
Here it’s strictly by rank - quality drops from the Large to the Small. However, the difference between the Large and the Base is not significant.
Next image:
 Source image
Source image
 Depth maps
Depth maps
The Large is the best. The Base barely distinguished the characters in the background, even the Small model identified them, though not as clearly as the Large.
Next image:
 Source image
Source image
 Depth maps
Depth maps
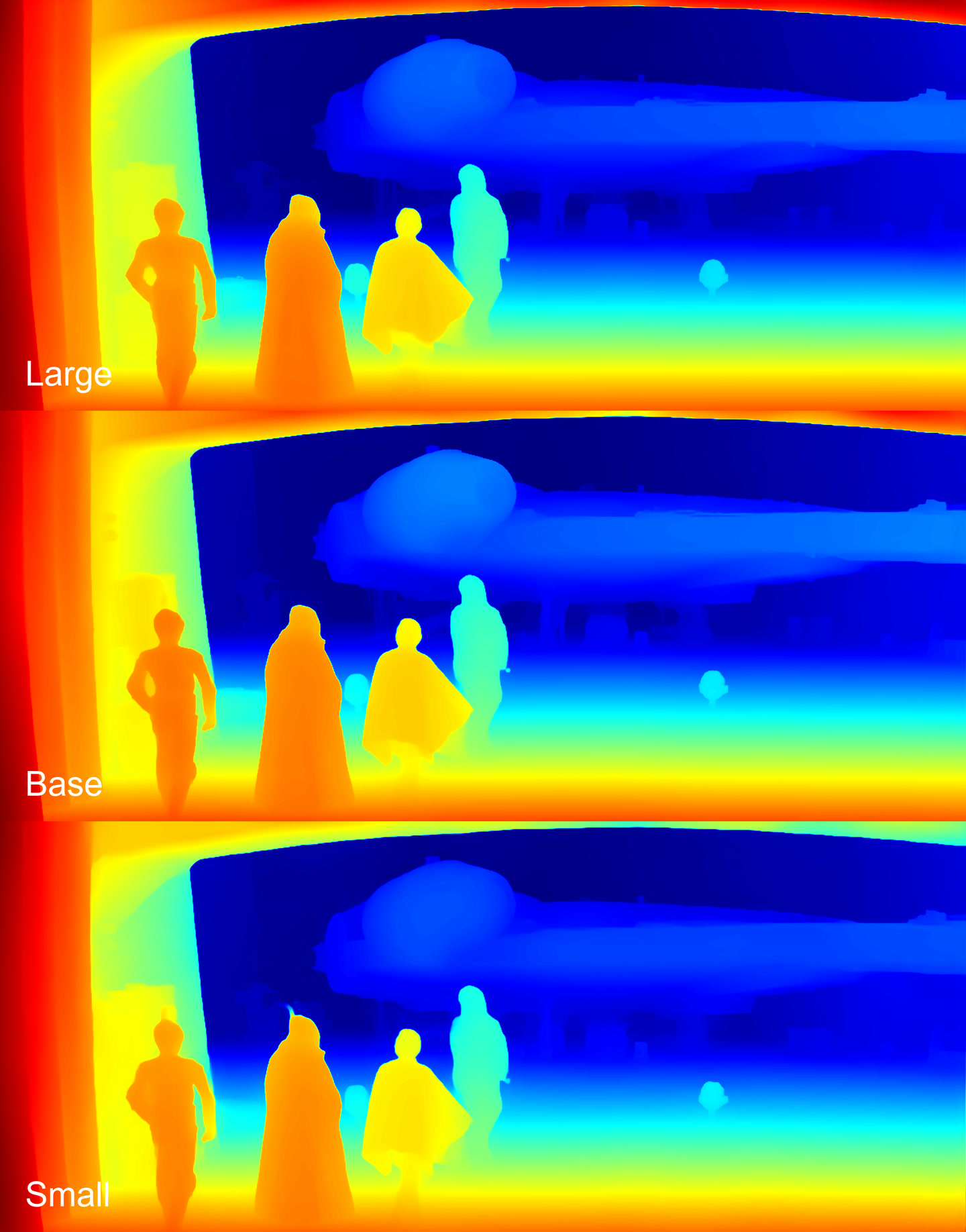
These results are very strange. The Base model failed to detect the character on the right. The Large model detected it but estimated its distance as greater than R2-D2 (the droid in the center). Only the Small model accurately determined the distances between all objects in the scene. Unfortunately, the Small model’s detail is noticeably worse
Next image:
 Source image
Source image
 Depth maps
Depth maps
I really like this frame because the depth levels are clearly separated here. All models performed well. But on the Large model, our long-suffering R2-D2 is more noticeable. On the Small model, you can clearly see the blurry contours of scene elements, which is characteristic of this particular model.
Next image:
 Source image
Source image
 Depth maps
Depth maps
All models performed well. Except that the Large model did not clearly define Luke’s legs (the 3rd character from the left), though this happens very rarely with this model.
Next image:
 Source image
Source image
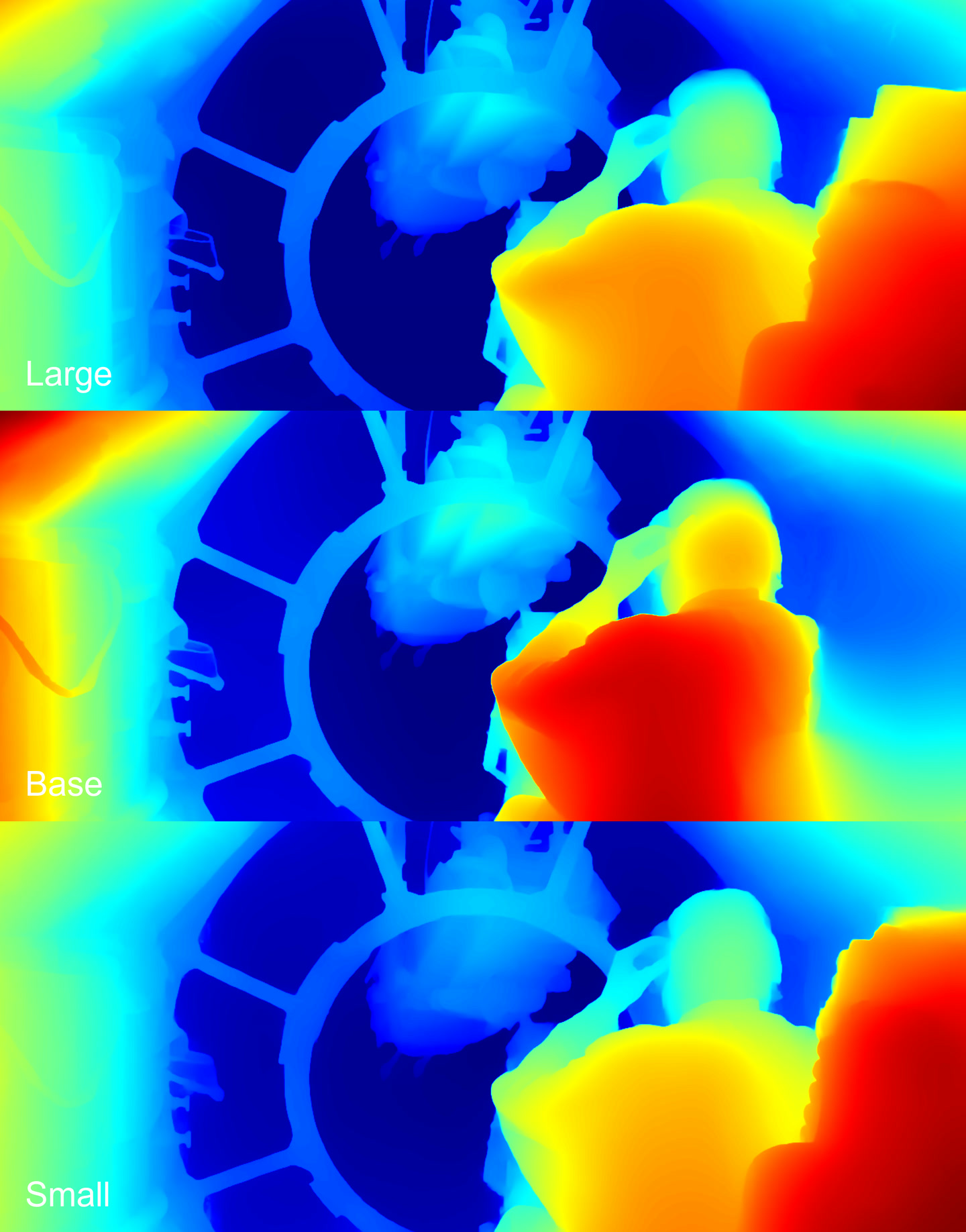 Depth maps
Depth maps
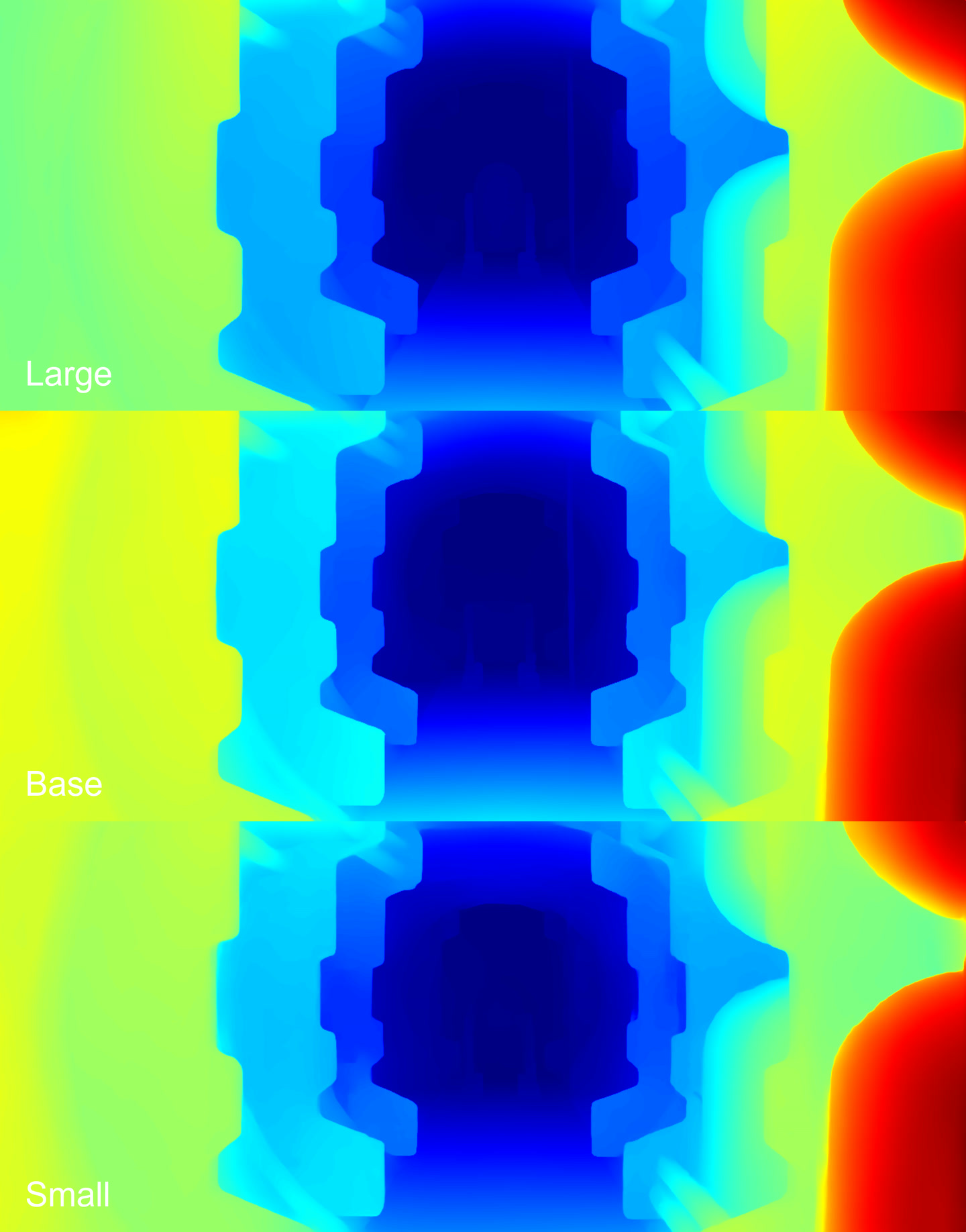
The Base model didn’t detect the chair behind the character. The other two defined everything well.
Next image:
 Source image
Source image
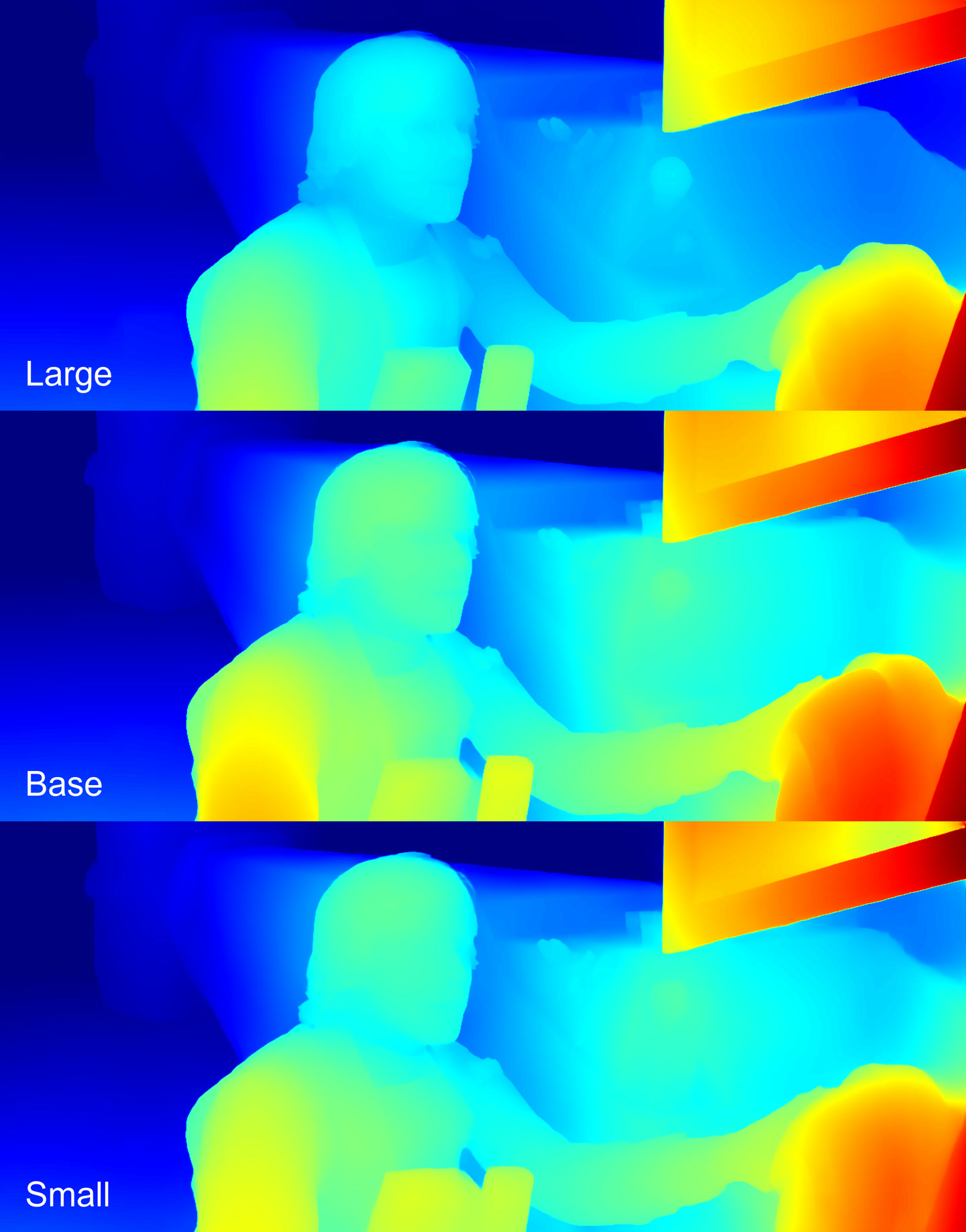 Depth maps
Depth maps
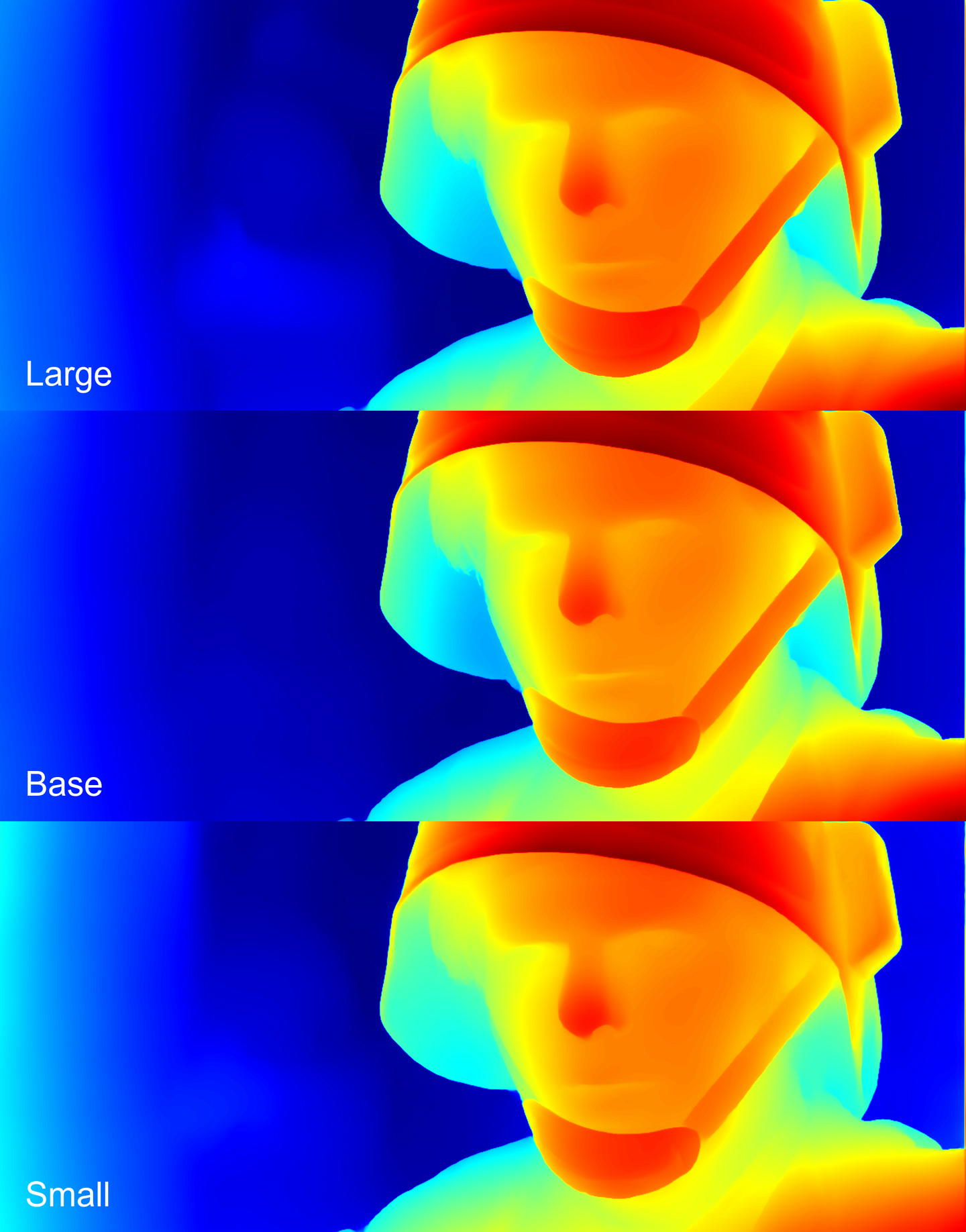
The Base and the Small models performed almost identically. The Large model detected more details, as is usually the case, especially noticeable in the character’s face.
Next image:
 Source image
Source image
 Depth maps
Depth maps
These results are practically identical to the previous frame.
Next image:
 Source image
Source image
 Depth maps
Depth maps
The Large and the Base models performed well, but for some reason on the Small model, Han Solo’s head almost merged into one with Chewbacca. Well, I suppose it’s friendship for the ages.
That’s probably enough.
Conclusion
All Depth-Anything-V2 models are good. The Large is more accurate and detect more details, especially in the background. The Small is the lightest and fastest model (according to my measurements, about 5 times faster than the Large), but significantly less detailed and poorly defines object contours. The Base model doesn’t lag far behind The Large in quality, but sometimes makes mistakes with object distances, while being about 2.5 times faster than the Large. Once again, there’s the approximate processing time for a 2-hour film from the main article:
The Large model: ~32 hours.
The Base model: ~13 hours.
The Small model: ~6 hours.
By the way, why Depth-Anything-V2 specifically? There’s no particular preference, really - it’s just the model that came to hand. More precisely, I first tested the Depth-Anything-V1, and then the Depth-Anything-V2; the latter met my current needs and produced very satisfactory results. As I wrote above, the Depth-Anything-V2 page also mentions a Giant model with 1.3B parameters. I’ve been waiting for it for several months now and it’s unknown whether it will be released at all. Perhaps by that time, higher quality models from other developers will appear - we’ll keep watching.
Thank you for your attention.
Additional materials
- See the main article about how to use Depth-Anything-V2 to create stereoscopic 3D
- Link to Google Drive with all images from this article